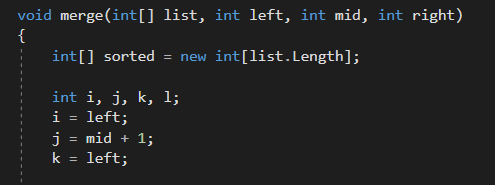
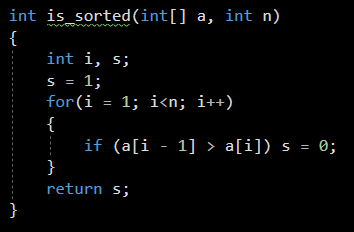
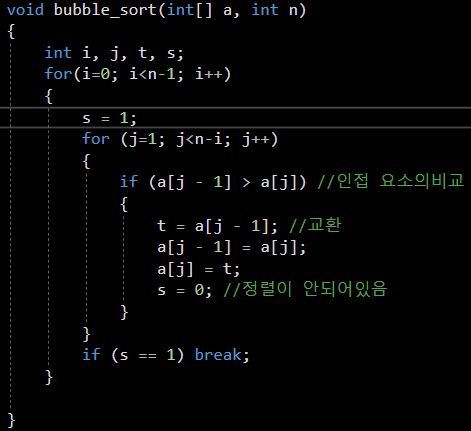
AVL나무
왼쪽 작은 나무의 높이와 오른쪽 작은 나무의 높이가 같거나 하나 차이나는 나무를 말한다.
AVL나무의 각 노드는 균형도라는 수치를 가지고 있는데 이는 왼쪽 작은 나무의 높이에 오른쪽 작은 나무의 높이를 뺀 값을 의미하며, 이 값의 절대 값이 클수록 나무 모양이 불균형하다는 뜻이 된다.
결국 AVL트리는 이진 검색트리이면서 동시에 균형을 유지하고 있는데, 균형이란 왼쪽과 오른쪽 높이의 차이가 1이하인 상태이다. (-1, 0 ,1)
이런 균형적인 구조를 지켜야 검색 시의 효율성을 보장할 수 있기 때문이다.

위에서 설명한대로
[균형도 = 왼쪽노드 레벨 - 오른쪽 노드 레벨]
식으로 계산하여 균형도는 절대값이 0과 1사이에 이어야 한다.
두 번째 그림처럼 균형이 무너진 유형중 하나인 LL구조이다.
AVL 불균형 구조는 회전방향과 회전 횟수에 따라 4가지로 구분된다.
1. LL : 균형도가 2인 경우


2. RR : 균형도가 -2인 경우

LL반대로 코드는 생략
3. RL :

4. LR


'알고리즘자료구조 > 검색&정렬알고리즘' 카테고리의 다른 글
| 검색알고리즘_이분탐색 (0) | 2019.04.12 |
|---|---|
| 검색알고리즘_순차탐색 (0) | 2019.04.11 |
| 정렬알고리즘_퀵정렬 (0) | 2019.04.07 |
| 정렬알고리즘_쉘정렬 (0) | 2019.04.06 |
| 정렬알고리즘_삽입정렬 (0) | 2019.04.05 |