인덱스 칼럼 순서에 따른 탐색 시간 비교해보기
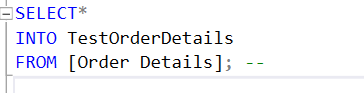
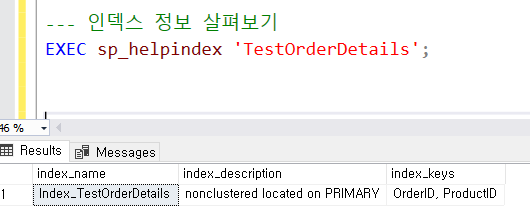
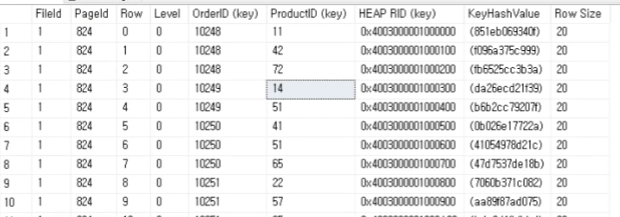
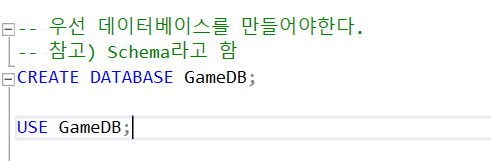
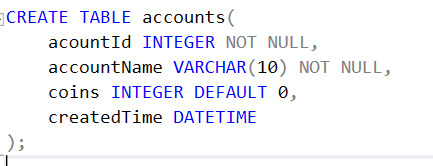
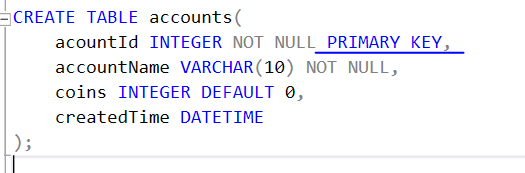
0. 테이블생성

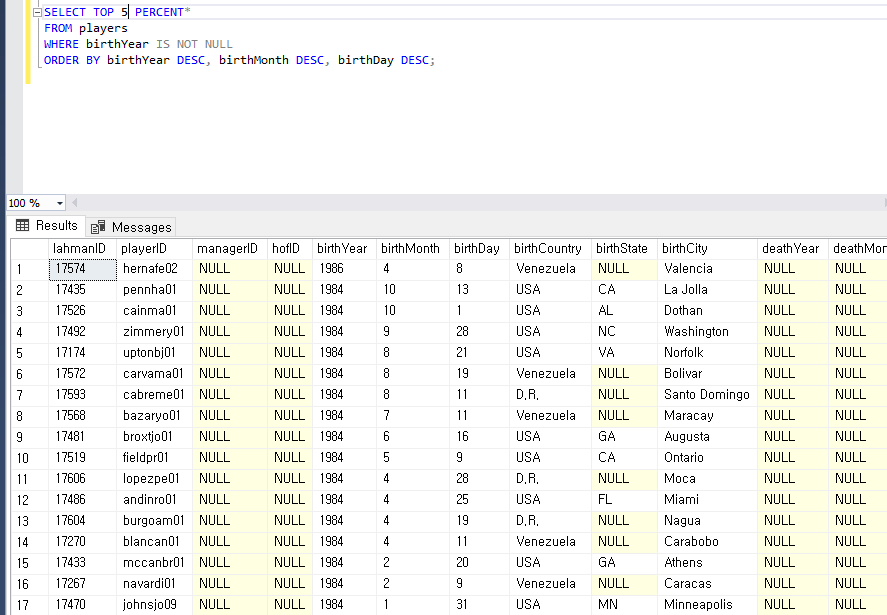
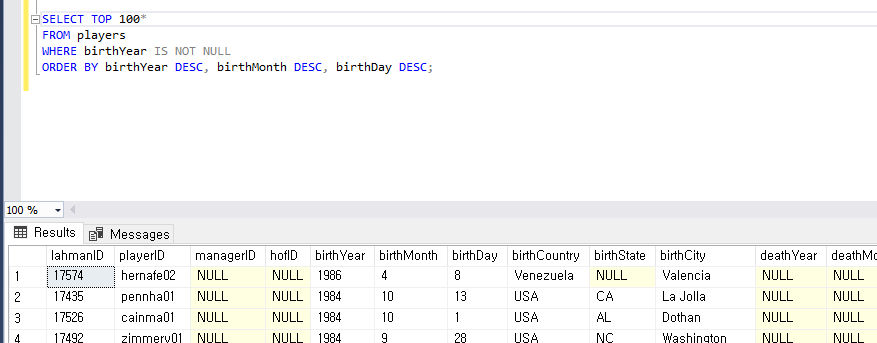
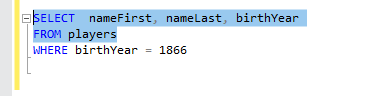
1. 정렬하기
1) ORDER BY EmployeeID, OrderDate;
EmployeeID로 정렬된 뒤에 OrderDate 순으로 정렬되어있다.
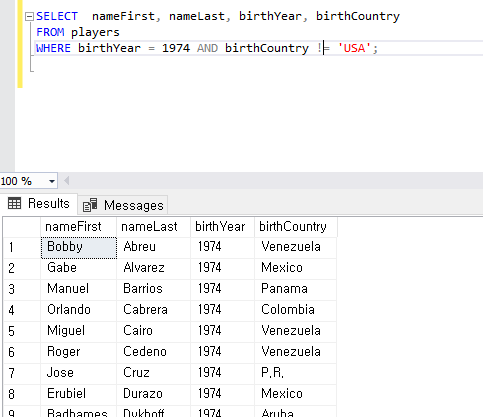
2) ORDER BY OrderDate, EmployeeID;
OrderDate , EmployeeID 순으로 정렬되어 있는 것을 알 수 있다.
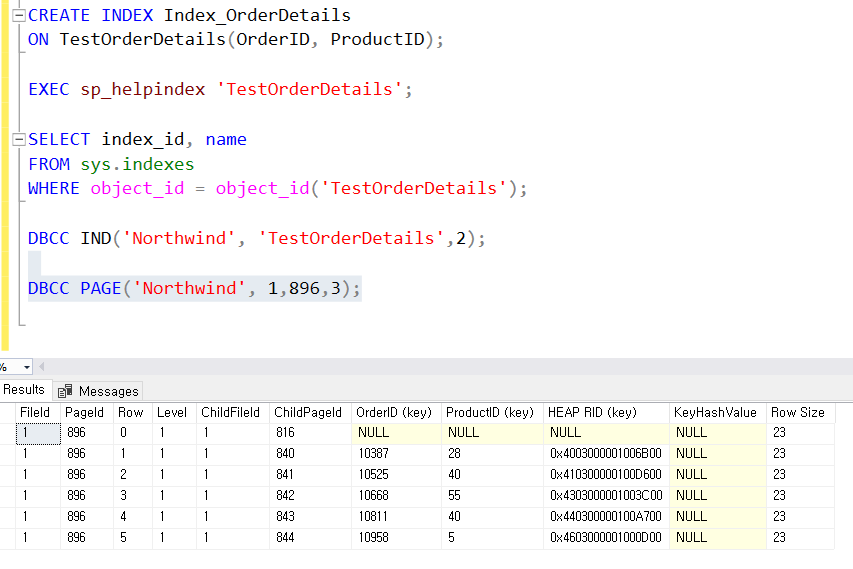
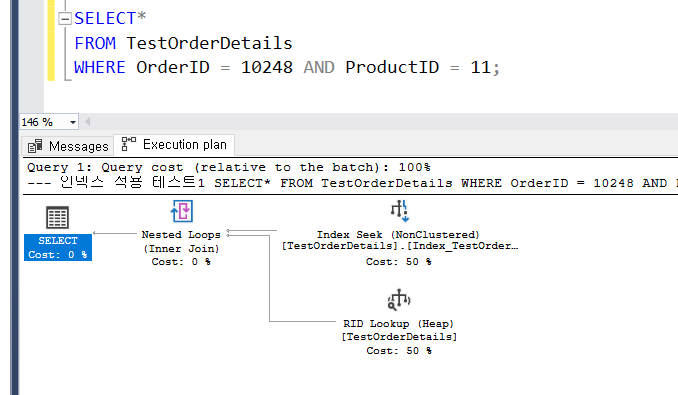
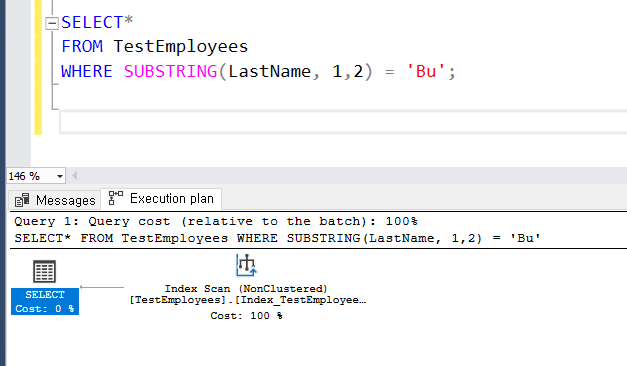
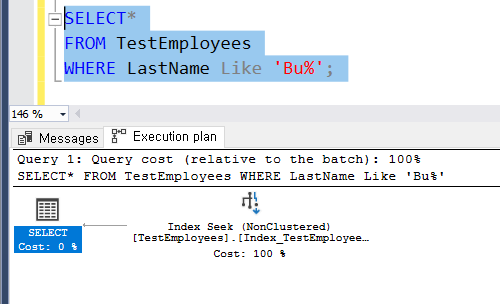
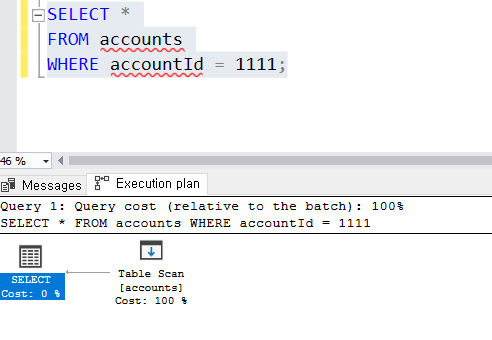
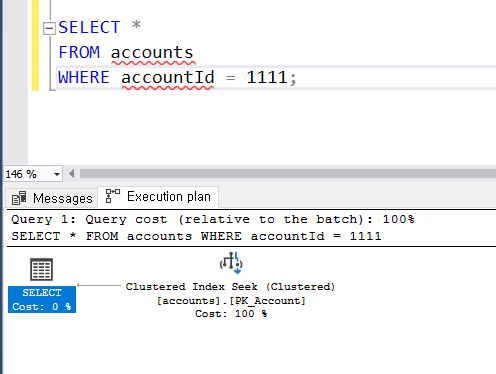
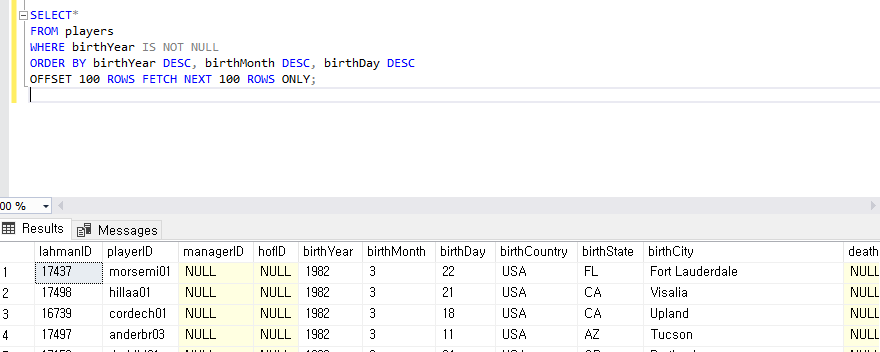
2. 특정 조건으로 찾기
SELECT *
FROM TestOrders WITH(INDEX(idx_emp_ord))
WHERE EmployeeID = 1 AND OrderDate = CONVERT(DATETIME, '19970101');
SELECT *
FROM TestOrders WITH(INDEX(idx_ord_emp))
WHERE EmployeeID = 1 AND OrderDate = CONVERT(DATETIME, '19970101');
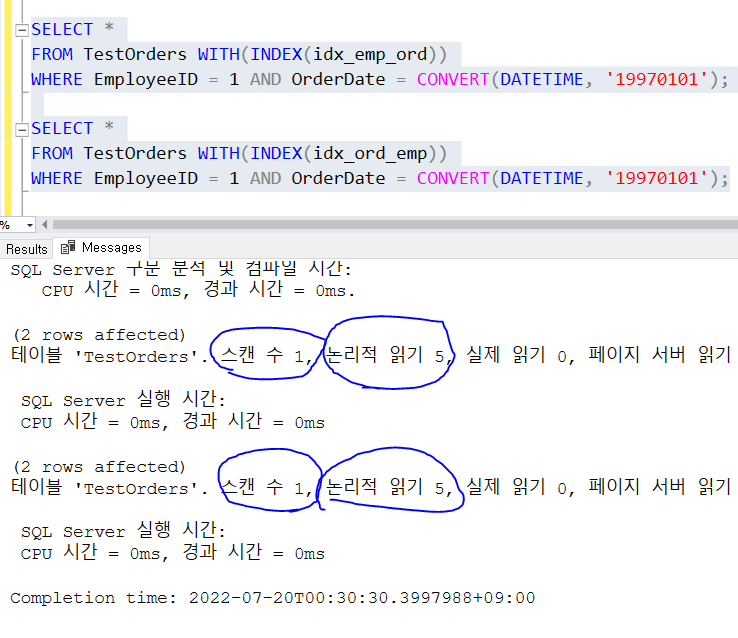
인덱스 조건이 다른 두 개 코드는 탐색 결과가 차이가 없는 걸 알 수 있다.
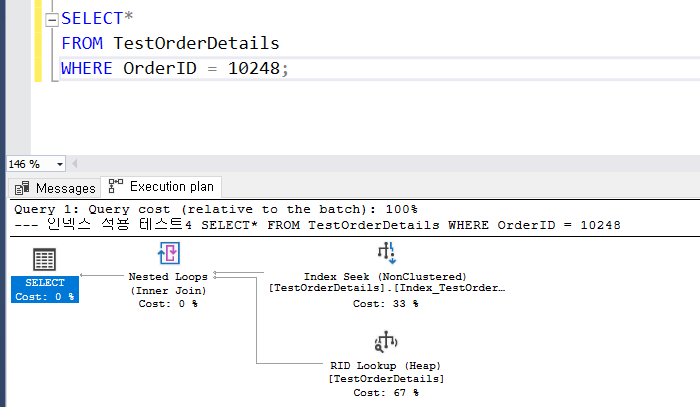
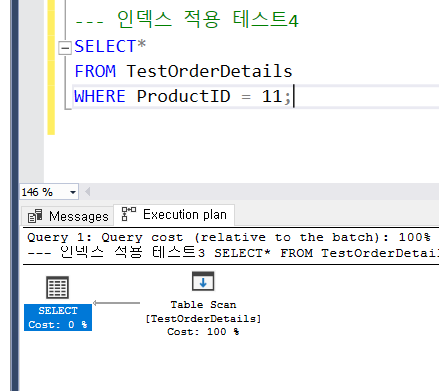
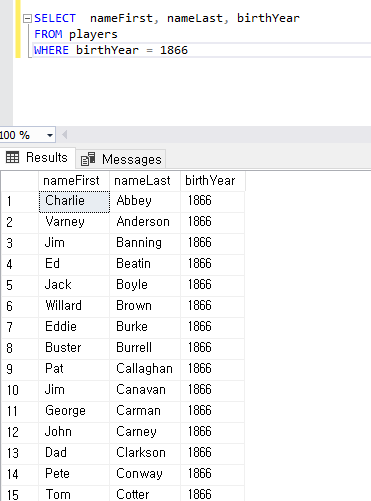
3. 범위 조건으로 찾기
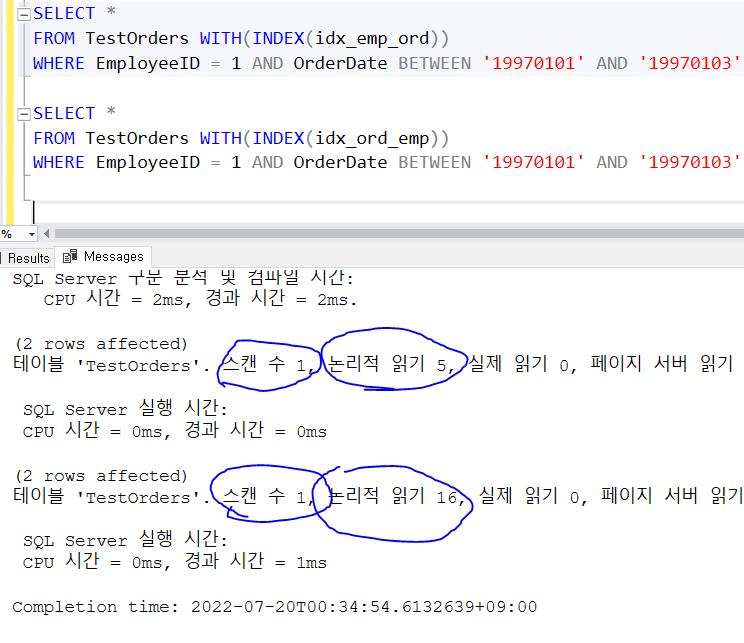
범위가 늘어나면 점점 큰 차이가 나게 된다. idx_emp_ord로 정렬한 뒤에 OrderDate범위는 바로 접근할 수 있는 반면에 idx_ord_emp로 정렬된 두 번째는 OrderDate를 범위를 찾은 다음에 다시 EmployeeID를 찾아야 하기에 더 오랜 시간이 걸리게 된다.
=> Index(a,b,c)로 구성되었을때, 선행 between사용하면 후행은 인덱스 기능을 살싱하게 된다.
'STUDY > 데이터베이스' 카테고리의 다른 글
| [SQL] 연습 Clustered / NonClustered (0) | 2022.07.16 |
|---|---|
| [SQL] 연습 복합인덱스 #4 (0) | 2022.07.12 |
| [SQL] 연습 DATABASE 작성 #3 (0) | 2022.06.30 |
| [SQL] 연습 ORDERBY #2 (2) | 2022.05.17 |
| [SQL] 연습 SELECT,WHERE #1 (0) | 2022.05.10 |