알고리즘을 공부하던중 재미있는 알고리즘을 발견해서 공부해보았다.
그것은 허프만 알고리즘.
허프만 알고리즘 Huffman
사용하는 빈도수의 따라 bit를 할당
자주쓰이는 문자에 가장 작은 bit를 할당
예를들어
HAN HA
이라는 문자열을 받으면
가장 많이 사용된 ‘H’에 0이라는 1bit를 부여하고
A에게 10, N에는 11을 할당한다.
(0)(10)(11) (0)(10)
당연히 중복된 문자가 많기 때문에 용량이 클수록 압축률은 올라간다.
코드부분
FileStream 부분

.txt 파일을 읽어 드리는 FileStream부분이다.
Header h = Compressor.Compress(bytes); 압축과정을 거친 후
h.Write(bf); 출력
압축과정

딕셔너리에 추가하면서 문자중복이라면 nVal(빈도수 )을 증가 시킨다.

노드를 만들어주는 과정 노드 빈도수의 합을 가지고 트리구조를 만듬

코드할당 부분 (01010) 왼쪽은 '0' 오른쪽 '1'
출력 코드 부분은 생략

보헤미안 랩소리 노래 앞부분을 txt파일에 넣음

빈도 수
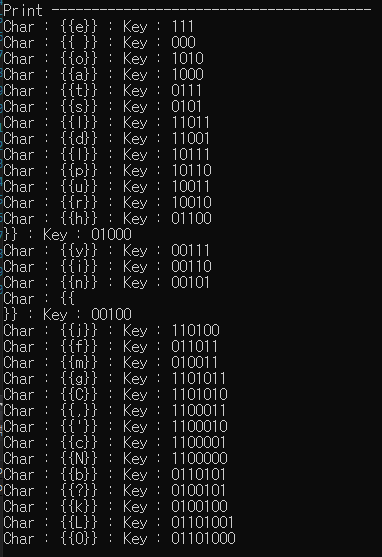

사실 노래앞부분만 넣었을 경우 내용이 짧기 때문 압축이 되지 않았다.
같은 문자를 여러번 복사해야 헤더가 물고있는? 문자들이 많이지기 때문에 압축률이 올라간다.
'알고리즘자료구조 > 자료구조' 카테고리의 다른 글
| C) 연결리스트 (0) | 2020.05.09 |
|---|---|
| C) 배열 기반의 연결 리스트 (0) | 2020.05.09 |
| Linked List 링크드 리스트(연결리스트)_단순연결리스트 (0) | 2019.03.25 |
| Linked List 링크드 리스트(연결리스트)_이중연결 리스트 (0) | 2019.03.24 |
| Stack 스택_연결리스트 구현 (0) | 2019.03.23 |