UML을 처음 알게 되었던 것은 클라이언트 프로그래머를 준비하기 위해 학원을 다니면서였다. 하지만 그때는 깊게 공부를 하지 않았었다. UML의 사용의 이유정도 였다. 딱히 필요성도 느끼지 못했었다. 10개월 동안 업무를 진행하면서 필요성을 조금 느꼈다. 그래서 다시 사이트를 검색하며 공부/정리하게 됐다.
1. UML
Unified Modeling Language의 약자이다. 소프트웨어 공학에서 사용되는 표준화된 범용 모델링 언어이다. 산출물을 만들때 미리 설계해 검증할 수 있으며 이것은 곧 문서화가 되게 된다. 문서화가 되면서부터 UML의 사용 이유가 생기게 된다.
작성한 코드의 구조를 한눈의 볼 수 있다.
추 후 유지보수의 대응이 빠르다.
그렇다고 모든 코드를 작성할 때마다 UML을 만들 필요는 없어 보인다. 실제로 작성하는 코드보다 UML의 문서화가 시간이 더 오래 걸릴 수 있기 때문이다.
2. 클래스 간의 관계도 표시방법
1. Generakization(일반화 관계) : 부모 클래스와 자식 클래스 간의 상속관 계를 나타낼 때.
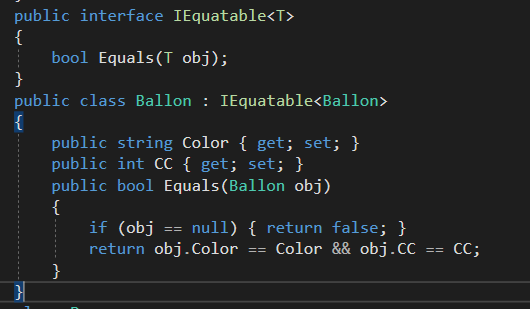
2. Realization (실체화) : 인터페이스를 구현하는 관계를 표현한다.
3. Association (연관 관계) : 한 객체가 다른 객체를 소유하거나, 참조하여 사용할 때, 단방향과 양방향이 존재한다.
- Aggregation (집합) : 약한 결합, 연결된 클래스와 독립적으로 동작된다. 메인클래스가 삭제될 시 대상 클래스는 같이 삭제가 안된다.
- Composition (합성) : Aggregation보다 강한 결합으로 이루어져 있어 라이프 사이클이 같아(같이 사라짐) 독립적이면 의미가 없다.
4. Dependency (의존 관계) : 서로의 객체를 소유하지는 않지만, 객체의 변경이 이루어질 때 따라서 같이 변경을 해주어야 할 때 사용한다. 대상 클래스를 생성해주고 바이바이
모바일에서 게임 플레이 중에 홈버튼으로 나가게 된다면 애니메이션이나 프레임은 어떻게 동작하는 것이 궁금하여 큐브가 회전하는 간단한 애니메이션을 만들어 테스트해봤다.
유니티 에디터에서 모바일에서 홈버튼이 눌린 상태를 만들기 위해서는 아래와 같은 세팅이 필요하다.
Run In Background 체크를 해제한다. 그러면 유니티 에디터 창이 비활성화 상태를 만들면 게임은 멈추게 된다.
그럼 이제 몇 가지 테스트를 해보자
1. 애니메이터 Update Mode : Normal / WaitForSecondsRealtime
void Start()
{
Debug.Log("Test 시작");
StartCoroutine(CorTest());
}
public IEnumerator CorTest()
{
yield return (CorWaitForRealSeconds());
}
private IEnumerator CorWaitForRealSeconds()
{
yield return new WaitForSecondsRealtime(5);
Debug.Log("Test2 WaitForSecondsRealtime 5seconds");
}
//애니메이션 이벤트 콜.
public void AnimEnd()
{
Debug.LogError("AnimEnd");
}
에디터가 시작하면 CorTest를 시작하면서 RealSeconds로 5초를 기다린 후 로그를 출력하고, AnimEnd는 애니메이션에서 6초에 이벤트 키를 넣었다.
정상적으로 아무 동작을 하지 않으면 차례대로 5초 뒤에 "Test 2 WaitForSeconds 5 seconds"을 출력하고 그다음에 1초 뒤에 곧이어 "AnimEnd"을 출력하게 될 것이다.
예상 : "Test 2 WaitForSeconds 5 seconds" -> 1초 뒤 "AnimEnd"
에디터가 활성화되어있지 않을 때는 애니메이션이 멈추는 것을 볼 수 있다. 5초쯤에 유니티를 클릭하면 바로 "Test 2 WaitForSecondsRealtime 5 seconds"을 출력하게 된다. 그리고 "AnimEnd"은 1초가 아닌 약 5초 뒤에 출력하게 되는 것을 볼 수 있다.
결과 : "Test 2 WaitForSeconds 5 seconds" -> 약 5초 뒤"AnimEnd"
테스트 결론 : 비활성화되었을 때도 WaitForSecondsRealtime은 계속해서 흐르지만 애니메이션은 활성화 되었을때 다시 카운팅을 하는 것이다.
2. 애니메이터 Update Mode : Unscaled Time / WaitForSeconds
void Start()
{
Debug.Log("Test 시작");
StartCoroutine(CorTest());
}
public IEnumerator CorTest()
{
yield return StartCoroutine(CorWaitForSeconds());
//Debug.LogError("CorTest");
}
private IEnumerator CorWaitForSeconds()
{
yield return new WaitForSeconds(5);
Debug.Log("Test2 WaitForSeconds 5seconds");
}
//애니메이션 이벤트 콜.
public void AnimEnd()
{
Debug.LogError("AnimEnd");
}
애니메이션 이벤트 콜은 6초이기 때문에 WaitForSeconds 5 seconds 후 1초 뒤에 AnimEnd가 불려야 하지만
애니메이터는 Unscale Time이기 때문에 비활성화 상태에도 시간은 흐른다. 그렇기 때문에 "AnimEnd" 후 "WaitForSeconds 5 seconds"가 출력된다.
부모(베이스) 클래스 안에 있던 멤버 변수와 멤버 함수를 물려받아 새로운 클래스를 작성할 수 있게 된다. 객체지향 언어의 가장 큰 특징이며 장점이라고 생각된다.
1. 구현방법
class Person
{
~~~~부모
}
class Student : Person
{
~~~~자식
}
Person은 부모 클래스 Student는 자식 클래스라 보면 자식 클래스 옆에 : 을 사용하여 Person의 자식이라는 것을 정의한다.
2. 예시
class Person
{
private:
string name;
public:
Person(string name) : name(name)
{
}
string GetName()
{
return name;
}
};
class Student : Person
{
private:
int studentID;
public:
Student(int studentID, string name) : Person(name)
{
this->studentID = studentID;
}
void Show()
{
cout << "학생 번호 : " << studentID << '\n';
cout << "학생 이름 : " << GetName() << '\n';
}
};
int main()
{
Student student(1,"han");
student.Show();
system("pause");
}
Student라는 객체를 새로 생성하면서 생성자를 통해 학생 번호와 이름을 부여하고 있다. Student는 name이라는 변수는 없지만 Person(name)을 통해 부모의 변수의 값을 넣을 수 있게 된다.
실행 결과
3. 다중 상속
class TempClass
{
public :
void ShowTemp()
{
cout << "임시 부모 \n";
}
};
class Student : Person, public TempClass
{
private:
int studentID;
public:
~~~...
int main()
{
Student student(1,"han");
student.ShowTemp();
system("pause");
}
C#은 안되지만, C++은 다중 상속이 가능하다.
4. 장점
1) 코드 중복이 없어진다. 2) 함수 재활용이 가능해진다.
오버라이딩
상속받은 자식 클래스에서 부모 클래스의 함수를 사용하지 않고 자식 클래스의 함수로 재정의 해서 사용하는 것이다. 아래 예시를 보면 쉽게 이해가 될 것이다.
객체를 생성함과 동시에 멤버 변수를 초기화할 수 있다. 인스턴스화될 때 자동으로 호출되며, 클래스의 멤버 변수를 적절한 기본값 또는 사용자가 정의한 값을 갖는 인스턴스가 생성되는 것이다.
1. 구현방법
class Student
{
private:
string name;
int englishScore;
int mathScore;
public:
Student(string n ,int e, int m)
{
name = n;
englishScore = e;
mathScore = m;
}
};
일반 메서드를 작성하는 방법과 같다. 이름은 클래스 이름과 같게 설정해주면 된다.(반환 값은 없음) Student인 새로운 객체를 만들 때 name, englishscore, mathscore의 각각 해당하는 값을 할당해주면서 이 객체는 초기화된다.
2. 사용방법
1) 클래스 이름과 같아야함 2) 반환 값이없어야함
int main(void)
{
Student a = Student("Mr.Han",100,98); // Student 생성!
}
이렇게 해주면 끝!
Student* st1 = new Student("han" , 100, 98);
st1->NumberUp();
이런식으로 동적으로 생성할때도 생성자는 동작한다.
3. 디폴트 생성자
public:
//Student(string n ,int e, int m) //생성자 주석.
//{
// name = n;
// englishScore = e;
// mathScore = m;
//}
};
int main(void)
{
Student a = Student(); //매개변수 X
}
작성한 생성자가 없을때는 매가변수가 없는 기본 생성자로 인식한다. 멤버 변수들은 '0'혹은 'NULL'인 값으로 설정된다.
4. 복사생성자
매개변수의 값을 넘겨주는 일반 생성자와 다르게 객체를 넘겨 복사를 하도록 하는 생성자이다.
int number = 0;
class Student
{
private:
string name;
int englishScore;
int mathScore;
int num;
public:
Student(string n, int e, int m)
{
name = n;
englishScore = e;
mathScore = m;
}
Student(const Student &st)
{
name = st.name;
englishScore = st.englishScore;
mathScore = st.mathScore;
}
void NumberUp()
{
number++;
num = number;
}
void Show()
{
cout << "번호 " << num << "이름 " << name << "영어 " << englishScore << "수학 " << mathScore << '\n';
}
};
int main()
{
Student* st1 = new Student("han" , 100, 98);
st1->NumberUp();
Student st2(*st1);
st2.NumberUp();
st1->Show();
st2.Show();
system("pause");
}
st1을 만들고 st2를 만들때 생성자에 *st1을 넘김으로 써 st1을 그대로 복사한다. 각 Student객체는 NumberUp()으로 int number를 한개씩 증가 시켜 각각 num의 값을 다르게 넣도록 했다.
소멸자
객체의 수명이 끝났다고 판단되면 이 객체를 제거하기 위한 목적으로 사용된다. 객체의 수명이 끝났을 때 자동으로 컴파일러가 소멸자 함수를 호출한다. 클래스명 앞에 '~'기호를 사용하여 작성한다.
객체지향 프로 래밍은 특히 이 접근 제한자를 잘 사용할 필요가 있다. 객체지향 프로그래밍은 한 완제품을 생상하는 공장의 기계들과 같다고 생각하면 좋을 것 같다. 예를 들어 자동차 한 대를 만들어 내기 위해서는 엔진, 부품 등등 여러 가지 제작, 결합 과정을 거치게 된다. 이 공장 기계들은 서로의 어떻게 부품을 만들어 내는지, 전혀 알 필요가 없다. 공장 기계들은 설계자가 시킨 작업만 진행하면 된다. 서로의 작업들의 내용을 공유하지 않기 위해 필요한 것이 정보은닉이다.
프로그램도 프로그래머가 설계한 클래스, 함수를 통해 자기 자신의 작업만 진행하면 된다. 이 접근 제한자는 프로그램을 보통 한명이 만들 때보다 여러 프로그래머가 동시에 작업을 할 때 특히 확실히 필요하게 된다.
#include <iostream>
#include <string>
using namespace std;
class Student
{
private:
string name;
int englishScore;
int mathScore;
int getSum()
{
return englishScore + mathScore;
}
public:
Student(string n ,int e, int m)
{
name = n;
englishScore = e;
mathScore = m;
}
void show() { cout << name << " : [합계 " << getSum() << "점]\n"; }
};
int main(void)
{
Student a = Student("Mr.Han",100,98);
a.show();
system("pause");
}
형식이나 멤버, 연산을 구체적으로 결정하는 과정을 말한다. 변수를 예로 들면, 변수를 구성하는 식별자, 자료형 속성, 하나 이상의 주소, 자료 값에 구체적인 값으로 확정하는 것을 말한다. 이런 바인딩을 하는 시점에 따라 동적 바인딩, 정적 바인딩으로 나뉜다.
동적 바인딩
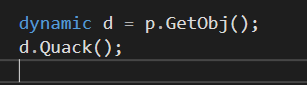
실행 시점에 진행되는 바인딩이다. 동적 바인딩은 컴파일 시점에서 어떤 함수나 멤버, 연산이 존재한다는 점을 프로그래머 자신을 알고 있지만 컴파일러는 알지 못하는 경우에 유용하다.
dynamic 키워드를 이용해 선언한다. 프로그래머는 d의 Quack()라는 함수가 있다고 가정하고 코드를 작성한다. 이렇게 하면 적으로 d와 Quack()은 바인딩된다.
정적 바인딩
먼저 컴파일러는 p의 GetObj() 이름의 매개변수 없는 메서드를 찾는다. 그런 메서드가 없으면 컴파일러는 선택적 매개변수를 받는 메서드, 그다음에는 Progoram의 기반 클래스에 있는 메서드 여기에도 없으면 확장 메서드까지 찾는다. 없으면 컴파일 오류를 뱉는다. 정적 바인딩은 컴파일러가 바인딩을 과정을 수행하며 이미 선언되어 컴파일러가 확실하게 파악된 형식만 가능하게 되는 것이다.
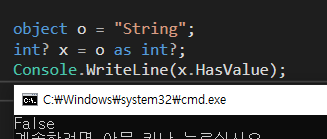
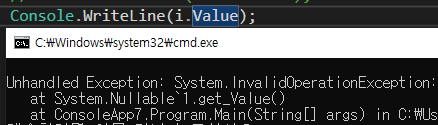
컴파일러는 T를 가벼운 불변이 구조체인 System.Nullable<T>로 바꾸어 컴파일한다. 이 구조체에는 두가지 필드가 존재한다. Value와 HashValue라는 두 필드만 있다.
아시다시피 C#에서 정수,구조체 등은 Value타입들은 null을 가질 수 없다. 하지만 이런 값타입도 값이 할당되지 않은 상태를 표현하고자 하려할때 Nullable구조체를 사용한다.
컴파일러는 위쪽 코드를 아래와 같이 바꾸어서 컴파일한다.
HashValue가 거짓인 널 가능 객체의 value를 조회하려 하면 InvalidOperationException이 발생한다. GetValueOrDefault()메서드 HashValue가 참이 면 value를 돌려주고 그렇지 않으면 new T()또는 지정된 커스텀 기본값을 돌려준다.
1. 인터페이스가 메서드를 하나만 정의할 때 & 3. 여러 종류의 메서드를 인터페이스를 여러 번 구현해야 한다
위 예시처럼 ITransformer인터페이스는 메서드를 하나만 가지고 있다. 이럴 경우 왜 델리게이트 더 좋냐면, 인터페이스 같은 경우 하나의 클래스에서는 하나의 메서드만 넘길 수 있는 반면에 델리게이트로 구현하게 되면 다른 메서드(int로 반환하는 메서드) 면 어떠한 메서드도 넘길 수 있기 때문이다.
델리게이트로 하면 Square 1도 되고~ Square2되지만
인터페이스로는
각각 클래스에 인터페이스를 상속받아넘겨야 한다.
2. 다중 캐스팅 능력이 필요하다.
하나의 대리자 인스턴스가 여러 개의 메서드를 지칭할 수 있는 델리게이트 기능이 필요하다면. 예를 들어