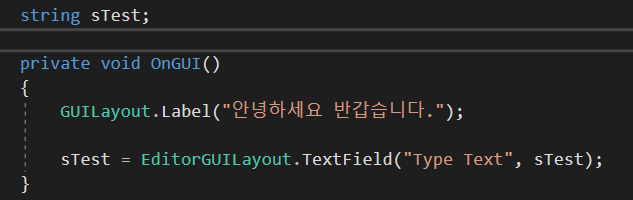
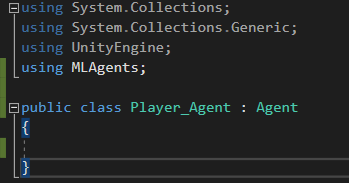
여러 형식들에서 재사용할 수 있는 코드를 작성하기 위한 메커니즘이 두 가지 있는, 하나는 상속이고 또 하나는 제네릭이다. 이 둘은 개별적인 메커니즘으로 상속은 기반 형식을 이용해서 재사용성을 표현하는 반면, 제네릭은 '자리표'에 해당하는 형식들은 담은 '템플릿'을 통해서 재사용성을 표현한다. 상속과 비교할 때, 제네릭을 사용하면 형식 안전성이 증가하고 캐스팅과 박싱이 줄어든다.
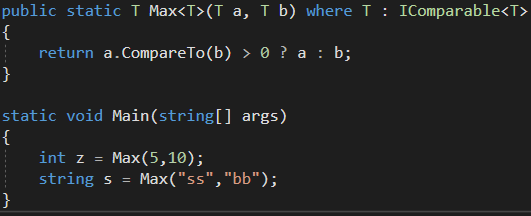
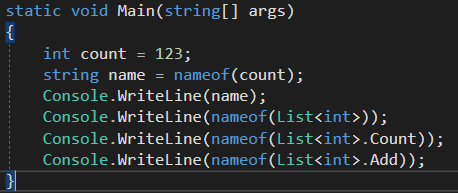
제네릭 형식
형식 매개변수(type parameter)들을 선언한다. 형식 매개변수는 제네릭 형식이 실제로 쓰일 때 해당 코드가 제공한 실제 형식들이 대신할 자리를 표시하는 '자리표에'해당한다. 말이 어렵지 어떻게 사용하는지 보면 쉽게 이해할 수 있다.
간단하게 스택을 제네릭 형식으로 만든 예제이다. 이렇게 만드면 타입을 상관없이 스택에 담을 수 있게 된다.
적용방법
이렇게 타입별로 클래스를 인스턴싱한 후 원하는 타입으로 사용할 수 있다. 이렇게 하면 위에서 나온 재사용이 가능해진 것이다.
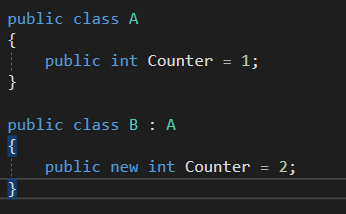
Object형식으로 만들면?
모든 타입을 포함하는 상위 클래스인 Object형식으로 스택을 만들면 가능하지만 이 제네릭과는 조금 다르다. object로 담을 수 있기 때문에
이런 식으로 여러 타입의 값들을 같은 배열에 담을 수 있다.(이렇게 사용하지는 않을 것 같음) 하지만 이것 자체가 박싱이며, 값들을 꺼낼 때도 하향 캐스팅이 필요하다. 박싱과 하향 캐스팅 둘 다 컴파일 시점에서 형식 점검이 일어나지 않기 때문에 실수할 가능성이 높다.
지금은 아무 에러가 없지만 프로그램을 실행하면 컴파일 에러가 난다.
제네릭 스택은 인스턴스를 만들때 한번 설정한 타입으로 컴파일 시점에서 점검이 이루어지기 때문에 안전하게 사용이 가능한 것이다.
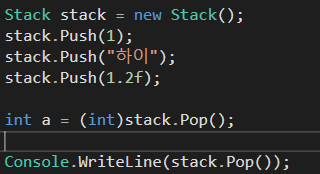
Object형식은 모든 형식의 궁극적인 기반 클래스이다. 그 어떤 형식도 Object로 상향 캐스팅할 수 있다. 범용적으로 쓰이는 Stack구조를 살펴보자
class Stack
{
public int Position;
object[] array = new object[10];
public void Push(object o)
{
array[Position++] = o;
}
public object Pop()
{
return array[Position--];
}
}
static void Main(string[] args)
{
Stack stack = new Stack();
stack.Push("Apple");
string answer = (string)stack.Pop(); //하향 캐스팅
}
그 어떤 형식의 인스턴스라도 push와 pop이 가능하다. 하지만 Object형식이기 때문에 Pop을 할 때는 명시적 캐스팅이 필요하다. 또, object는 하나의 클래스이며, 따라서 참조 형식이다. 그렇긴 하지만 int 같은 값 형식과 object사이의 캐스팅도 가능하다. c#의 이러한 특징을 형식 통합이라고 부른다.
Object(참조) 형식도 int(값) 형식으로 변환이 가능하다.
박싱과 언박싱
위에서 살짝 언급한 내용으로 값 형식 인스턴스를 참조 형식 인스턴스로 변환하는 것을 박싱이다. 그럼 그 반대는? 언박싱이겠지라고 생각하는데 맞기는 하는데 한 가지 조건이 있다. 바로, 박싱 과정을 거친 객체를 되돌리는 것이 언박싱이다.
간단한 예제로 살펴보자
1.박싱
int x = 10;
object obj = x; //int 박싱
1.언박싱
int x = 10;
object obj = x; //int 박싱
int y = (int)obj; //int 언박싱
박싱은 그냥 하면 되고, 언박싱은 명시적 캐스팅이 필요하다. 이렇게 쉽게 참조 타입과 값 타입 사이에서 형식 변환을 쉽게 할 수 있다는 것은 매우 편리하다. 모든 함수와 자료구조 타입을 objct형식으로 만들어놓으면 캐스팅만 잘 사용한다면 코드 중복 없이 짧고 쉽게 설계가 가능할 것 같아 보인다. (이 세상에서 분명 공짜는 없다. 박싱과 언박싱에서는 단점이 있다. 다음에 설명 )
하지만, 기억해야 할 것은 objct는 참조 형식이고, int는 값 형식이다.
박싱과 언박싱의 복사 의미론
박싱(값 -> 참조)은 값 형식 인스턴스를 새 객체로 복사하고, 언박싱(참조 -> 값)은 객체의 내용을 다시 값 형식 인스턴스로 복사한다. 말로 풀었을 때 무슨 소리인지 모르겠다. 이 과정은 어떤 과정인지 한 가지 예를 보고 살펴보자.
int i = 5;
object boxed = i;
i = 3;
Console.WriteLine(boxed);
Console.WriteLine(i);
Console.WriteLine(boxed);
먼저 출력 결과를 먼저 알려주면 위에서부터 5,3,5이다. 답을 맞혔다면 저 말을 이해가 된 것이다. boxed와 i는 서로 다른 인스턴스 즉, "i는 boxed라는 새로운 인스턴스를 만들고 자신의 값을 복사했다."라는 말이다. 그래서 i의 값을 바꿔도 boxed의 값은 변경되지 않는다.
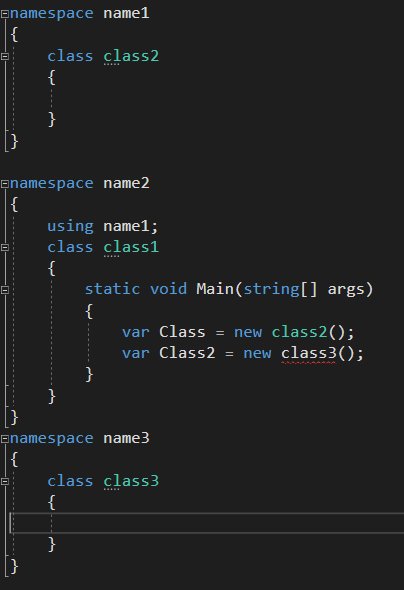
자식 클래스에서 부모클래스로 접근은 가능하지만 자식클래스에서 부모클래스의 생성자는 자동으로 상속되지 않는다.
class Parent
{
public int X;
public Parent() { }
public Parent(int X)
{
this.X = X;
}
}
class Child : Parent
{
}
class Program
{
static void Main(string[] args)
{
Child child = new Child(123); //컴파일에러
Console.WriteLine(child.X);
}
}
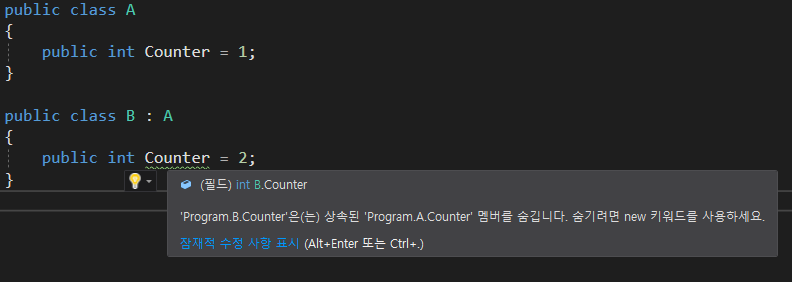
자식클래스는 자신이 노출하고자 하는 생성자들을 반드시 '다시 정의' 해야한다.
class Parent
{
public int X;
public Parent() { }
public Parent(int X)
{
this.X = X;
}
}
class Child : Parent
{
public Child(int X) : base(X) { } //base 키워드를 사용하여 상속
}
class Program
{
static void Main(string[] args)
{
Child child = new Child(123);
Console.WriteLine(child.X);
}
}
만약 base키워드를 쓰지 않고 매개변수가 없는 생성자를 호출하면 부모클래스의 매개변수가 없는 생성자가 실행된다.
class Parent
{
public int X;
public Parent() { }
public Parent(int X)
{
this.X = X;
}
}
class Child : Parent
{
public int y;
}
class Program
{
static void Main(string[] args)
{
Child child = new Child();
Console.WriteLine(child.X);
}
}
부모클래스에 접근 가능한 기본생성자가 하나도 없으면 자식클래스는 생성자에서 반드시 base클래스를 사용해야한다.
public class Asset
{
}
public class Stock : Asset
{
}
class Program
{
static void Main(string[] args)
{
Stock stock = new Stock();
Asset asset = stock;
}
}
상향 캐스팅 연산은 파생 클래스 참조로부터 기반 클래스 참조를 생성한다.
stock 와 asset가 가리키는 객체는 같다. (stock == asset는 true)
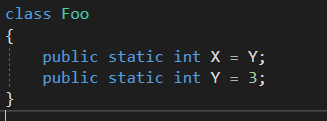
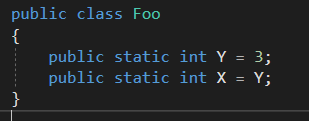
public class Foo
{
public static Foo Instance = new Foo();
public static int X = 3;
Foo() { Console.WriteLine(X); }
}
public class Asset
{
public int nInt;
}
public class Stock : Asset
{
public float fFloat;
}
class Program
{
static void Main(string[] args)
{
Stock stock = new Stock();
Asset asset = stock; //상향 캐스팅
Console.WriteLine(asset.fFloat); //컴파일 오류
}
}
stock형식의 객체를 가리키긴 하지만 변수 자체의 형식은 Asset이기 때문에 fFloat변수접근이 불가능하다.
하향캐스팅
하향캐스팅 역시 변하는 것은 참조 뿐이다. 하향은 실행시점에서 실패 할 수도 있기 때문에 명시적으로 캐스팅이 필요하다.
public class Foo
{
public static Foo Instance = new Foo();
public static int X = 3;
Foo() { Console.WriteLine(X); }
}
public class Asset
{
public int nInt;
}
public class Stock : Asset
{
public float fFloat;
}
class Program
{
static void Main(string[] args)
{
Stock stock = new Stock();
Asset asset = stock; //상향 캐스팅
Stock a = (Stock)asset; //하향 캐스팅
Console.WriteLine(a.fFloat);
Console.WriteLine(a.nInt);
Console.WriteLine(asset == stock); // true
Console.WriteLine(asset == a); // true
Console.WriteLine(a == stock); // true
}
}
as 연산자
as 연산자도 하향 캐스팅을 수행한다. 위와 다른점은 실패할 경우 null로 평가된다.
class Program
{
static void Main(string[] args)
{
Asset a = new Asset();
Stock s1 = (Stock)a;
Stock s2 = a as Stock; // 예외를 발생하지 않음
}
}
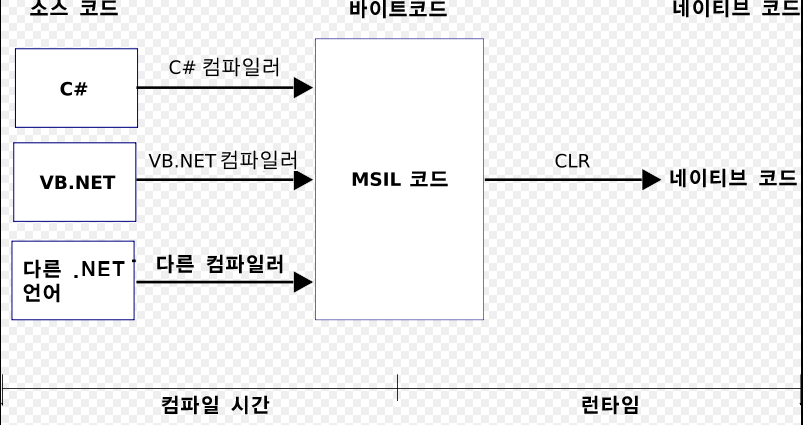
마이크로 소프트 이니셔티브에서 제공하는 가상 머신의 구성요소이다. 프로그램 코드를 위한 실행 환경을 정의하는 마이크로소프트의 공통 언어 기반(CLI)표준의 기능이다. C#이나 VB닷넷과 같은 언어로 프로그래밍하며, 해당 언어의 컴파일러가 소스 코드를 공통 중간 언어(IL) 코드로 변환한다.
CLR은 관리되는 코드(managed code)를 실행하기 위한 런타임이다. C#은 여러 관리되는 언어중 하나인데, 관리되는 언어로 작성한 소스코드를 컴파일 하면 관리되는 코드가 생성된다. 관리되는 코드를 실행 파일또는 라이브러리(.dll)형태로 만들고 그것을 형식 정보, 즉 메타자료와 함께 하나의 패키지로 묶은 것을 어셈블리라고 한다. 어셈블리를 적재 할 때 CLR은 IL코드를 해당 컴퓨터(x86 등) 고유의 기계어 코드로 변환한다. 이러한 변환을 담당하는 것이 CLR의 JIT(Just - in - time)컴파일러이다. 어셈블리는 원래의 원본 언어의 구성을 거의 그대로 유지하기 때문에, 코드를 조사하기 쉽고 심지어 동적으로 생성하기도 쉽다.
위캐백과
1.이니셔티브 : 우선권, 주도권, 스스로 상황 판단을하고, 남들이 움직이기 전에 먼저 움직일 수 있는 능력
2.CLI : Command-Line user Interface또는 Character User Interface
무한한 메모리를 가지고 있는 기기는 없기 때문이다. 그렇기에 텍스처 압축 기술을 통해 텍스처 역시 디스크나 메모리의 크기를 절약해야 한다.
메모리 이슈
텍스처는 수많은 비트 데이터들도 이루어진 이미지 데이터이다. 그렇기에 GPU가 이 데이터를 이용하려면 대역폭이 필요하고 성능이슈가 발생하게 된다. 우리가 원하는 것은 적은 메모리로 합리적인 품질을 내야한다. 그렇기에 텍스처 데이터 사이즈를 관리해야한다.
하지만 텍스처 사이즈는 대역폭만의 문제만이 아니라 메모리 문제도 있다. 복잡한 씬을 렌더링하거나 데이터 사이즈가 큰 텍스처들을 한꺼번에 많이 올려두는 경우들이 있다. 이런 문제는 PC보다는 적은 메모리에 모바일 디바이스에서 더 큰 문제로 다가 올 수 있다.
패키지용량 이슈(모바일)
모바일 앱마켓에서 게임을 받을 때 WIFI에서만 다운로드가 가능하거나 권장하는 문구를 본적이 있다. 이렇게 큰 용량의 앱들을 받게 될때 거부감이 들때가 있다. 특히 WIFI가 없는 곳에서는 더더욱! 그렇기 때문에 초기에 모두 받지 않고 설치 이후 패치등으로 데이터드를 다운로드 받게 하는데 이 역시도 너무 큰 용량이라면 거부감이 들 수있다.
압축방식
이미지 압축은 크게 손실압축과 비손실 압축으로 두 종류가 존재한다. 비손실 압축은 원본 이미지를 그대로 유지하면서 데이터만 압축하는 방식이며, 비손실 압축은 원본 이미지의 퀄리티를 어느정도는 훼손하는 대신에 데이터 압축 비율을 높여서 데이터 크기 절약에 집중하는 방식이다. JPG와PNG는 GPU가 바로 읽어 들일 수 없다. 그렇기 때문에 텍스처를 위한 별도의 압축 방식을 이용해야한다. 유니티는 어떤 이미지를 Import하면 원본 이미지 포맷이 PNG인지 JPEG인지 등은 상관없이 특정 포맷의 이미지로 변환하여 사용한다. 텍스처 압축은 플랫폼별 특성이 다르므로 플랫폼마다 적절한 압축 포맷을 설정해주는게 좋다.
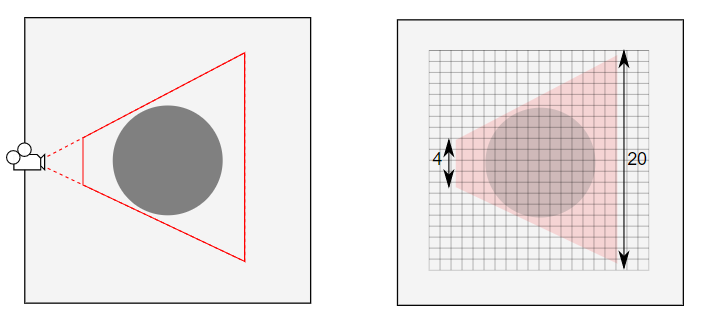
빛이 지나가는 경로에 불투명한 물체가 존재하여 빛이 통과하지 못해 생기는 어두운 부분이다. 게임에서 그림자는 모든 물체를 입체감을 더해주는 요소이다. 그림자가 있으면 사물의 공간산 위치를 인지하기 쉽게 만들어주기 때문이다. 유니티는 그림자 또한 쉽게 표현하도록 기능이 구현되어있다.
2. 그림자의 원리
유니티는 쉐도우맵기법을 사용하고 있다. 쉐도우 맵은 깊이 텍스처 값을 이용한 기법이다. 이 기법은 모든 굴곡에서 대응하고 셀프-쉐도우가 처리되는 등 높은 퀄리티를 보여준다.
쉐도우 맵의 원리? (포워드 렌더링)
먼저 뎁스 텍스처를 생성한다. 카메라를 통해서 현재의 씬이 렌더링 되는 정보를 렌더링 하는 과정이다. 렌더링 될 픽셀의 컬러 대신 카메라로부터 픽셀의 위치까지의 거리를 렌더링 한다. 카메라의 가까이 있는 픽셀일 수로 록 검은색, 멀 수록 흰색이다(그림자에 영향을 받는 모든 오브젝트들을 렌더링). 그 후 그림자 처리를 위한 별도의 버퍼가 필요하다. 이 버퍼에는 광원에서 바라보는 오브젝트의 픽셀의 깊이를 저장한다. 이 버퍼가 그림자를 위한 정보를 담아서 쉐도우 맵이다.
그림자의 깊이를 저장하는 버퍼를 만든 후 픽셀 쉐이더에서 깊이를 비교하는 과정을 진행한다. 또한 넓은 영역을 커버하기 위해 여러 구역으로 나누기도 하고 계단 현상을 없애기 위해 여러 번 샘플링하여 필터링 처리를 하는 부가 기능들을 추가한다. 그러다 보니 그림자가 렌더링 비용 중 많은 부분을 차지하게 된다.
뎁스 텍스처와 쉐도우 맵이 완성되면 뎁스 텍스처에 있는 정보와 쉐도우 맵에 있는 정보를 비교하여 그림자 영역을 계산한다. 뎁스 텍처에 있는 픽셀들을 순회하면서 해당 픽셀을 광원으로부터의 거리로 변환하여 비교한다.
2. 어떤 그림자를 이용해야 할까
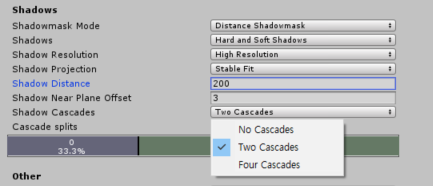
물론 실시간으로 그림자를 활성화시키고 유니티의 그림자 구현능력을 믿어보면 간단하고 편하다. 하지만 그림자를 렌더링 하는 것은 높은 성능을 요구하기 때문에 이렇게 그냥 맡기는 것은 무책임하다. 그렇기에 만들려는 게임이 무엇인지, 어떤 디바이스를 타깃으로 만들 건지 생각하고 그에 맞는 세팅이 필요하다.
아래는 유니티가 제공하는 컴포넌트에서 쉽게 설정할 수 있는 셋팅방법이다.
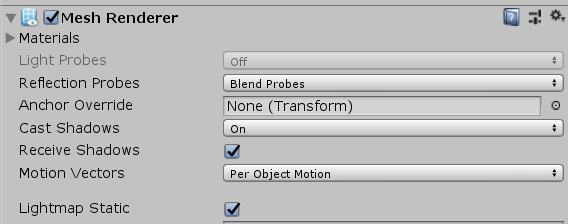
Mesh Renderer는 메쉬 필터의 지오메트리를 사용하여 오브젝트의 Transform컴포넌트에서 정의된 위치에서 렌더링 한다. 프로퍼티를 간단하게 살펴보면
Cast Shadows : 그림자 라이트가 비춰질 때 메쉬가 그림자를 만든다.
ReceiveShadows : 오브젝트에 다른 오브젝트의 그림자를 받는 설정이다. 실시간으로 그림자가 적용된다.
1. 그림자를 필요로 하지 않는 오브젝트인 경우는 CastShadow를 꺼놓아야 드로우콜을 절약할 수 있다.
2. ShadowsOnly로 선택하면 최종 화면에는 렌더링 되지 않지만 쉐도우 맵에는 반영되어 그림자를 만드는 오브젝트가 된다. 즉 화면에는 보이지 않는 특성이 있어 그림자 처리만을 위한 3D 모델에 활용할 수 있다.
씬뷰에는 메시만 보이고 게임 뷰에서는 그림자만 보인다.
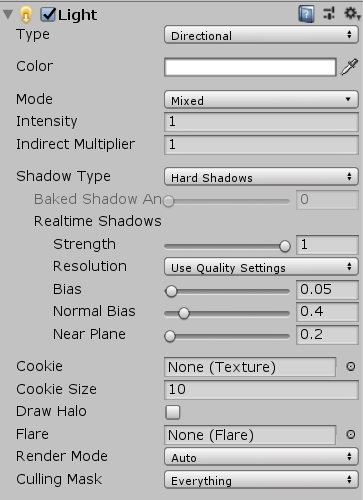
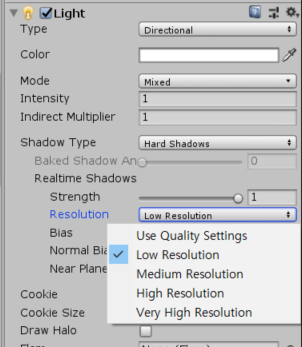
3. Light -> Shadow Type
Soft Shadows 가 좋은 만큼 성능도 많이 차지한다. 픽셀 쉐이더의 부담이 된다. 모바일이라면 되도록 HardShadows를 사용한다.
드로우 콜에 대해서 알았다면, 이제 이것을 줄이는 방법을 알아야 한다. 가장 효율적인 방법으로 배칭이 있다. 효율적인 방법이라고 한 것은 여러의 배치를 하나로 묶어서 하나의 배치로 만드는 것이 바로 배칭인 것이다. 한 가지 예를 들어보면 오브젝트가 3개 있다면 원래는 3개의 드로우 콜 즉, 3개의 배치가 필요하지만 조건에 따라서 1개까지 줄이는 것이다. 메시가 서로 다른 오브젝트이지만 같은 머테리얼을 사용하면 하나의 배치로 만들 수 있다.
배칭을 위해서는 다른메시를 이용하더라도 머티리얼을 공유해서 사용해야 한다. 파츠가 여러 개인 경우 메시는 각각 다르지만 하나의 머티리얼을 통해 색상을 입히는 것이다. 이렇게 하기 위해서는 여러 장의 텍스처를 하나를 묶어 텍스처 아틀라스 기법으로 하나의 텍스처로 여러 메시들이 사용할 수 있게 하는 것이다.
같은 머테리얼이라는 의미는 동일한 인스턴스를 말하며, 같은 텍스처를 사용하는 머테리얼이지만 그것이 2개라면 같은 인스턴스가 아닌 것이다.
다른 머테리얼
이러한 이유로 코드상에서 머티리얼을 접근할때 유의할 점이있다. 머테리얼 색상을 바꾸는 코드는 GetComponent<Renderer>().material.color = Color.red;을 사용하면 색상을 바꿀 수 있다. 하지만 이 코드를 사용할 때마다 계속해서 새로운 머테리얼을 복사 생성하게 된다. 그러면 다른 머테리얼의 인스턴스를 생성하는 것이다. 하지만 같은 인스턴스를 사용하는 방법도 있다. 머테리얼의 속성을 바꾸는 Renderer.sharedMaterial을 사용하면 된다. 물론 상황에 따라 사용하겠지만 한 가지 예시로,
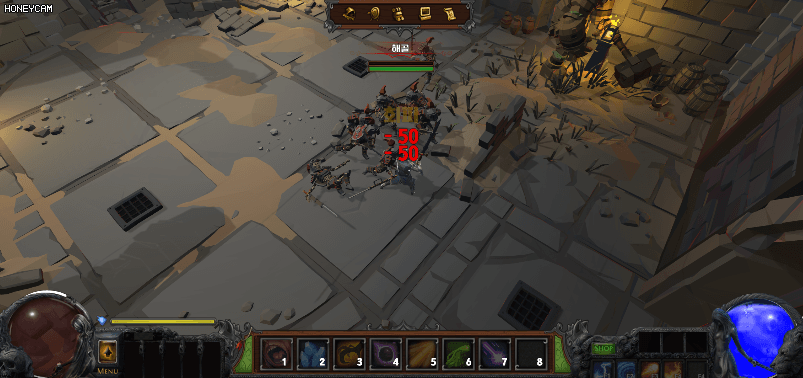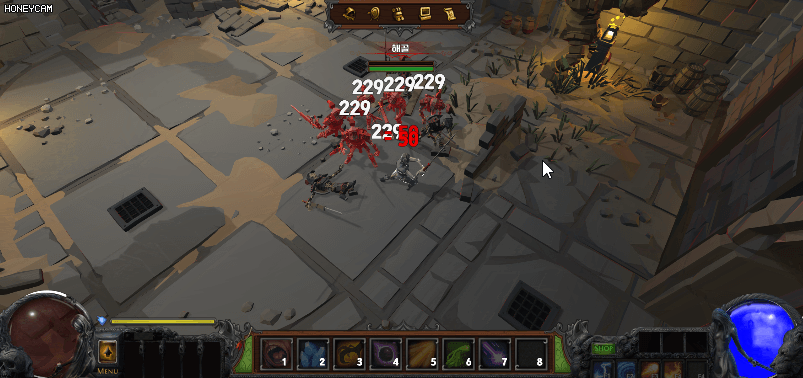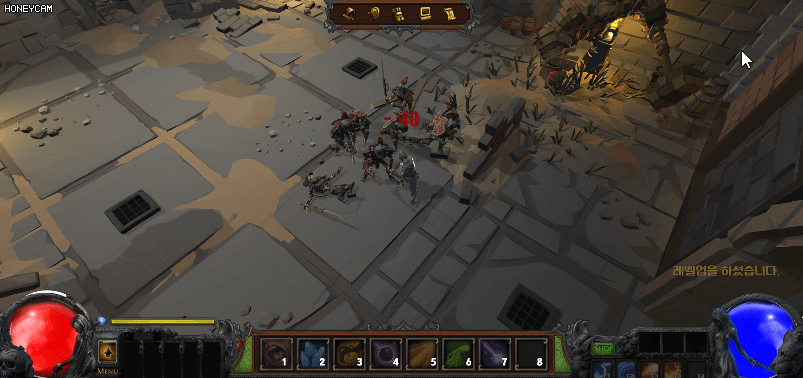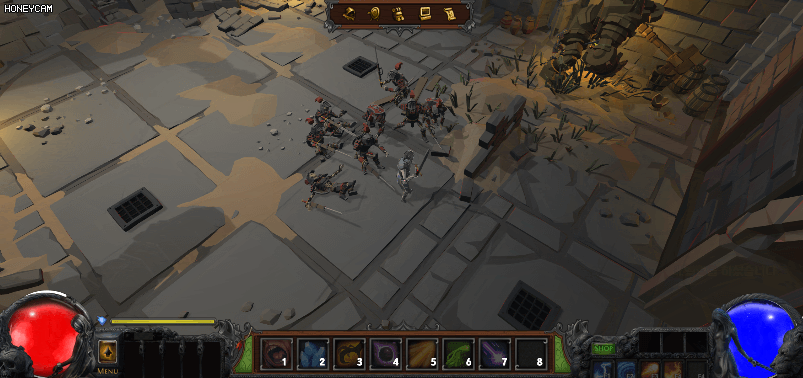
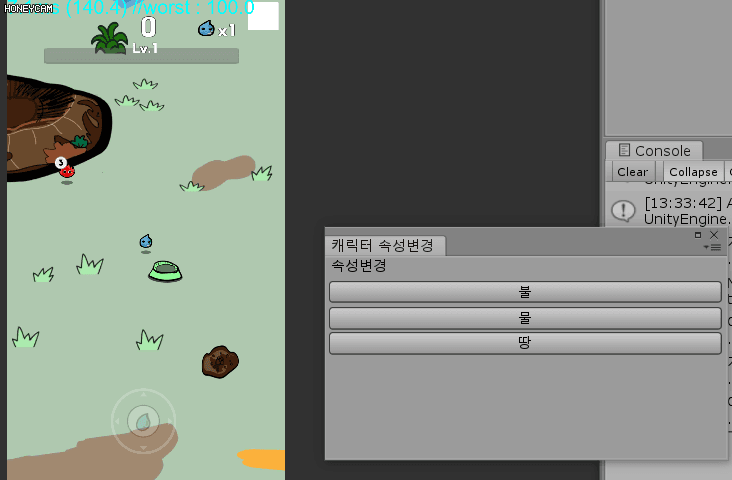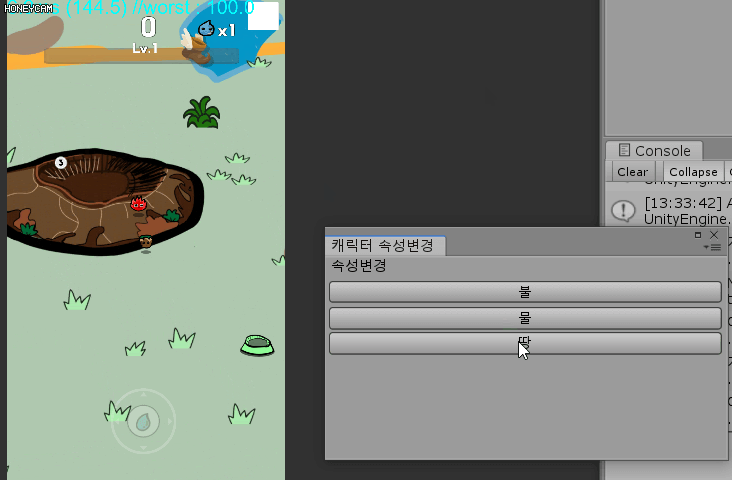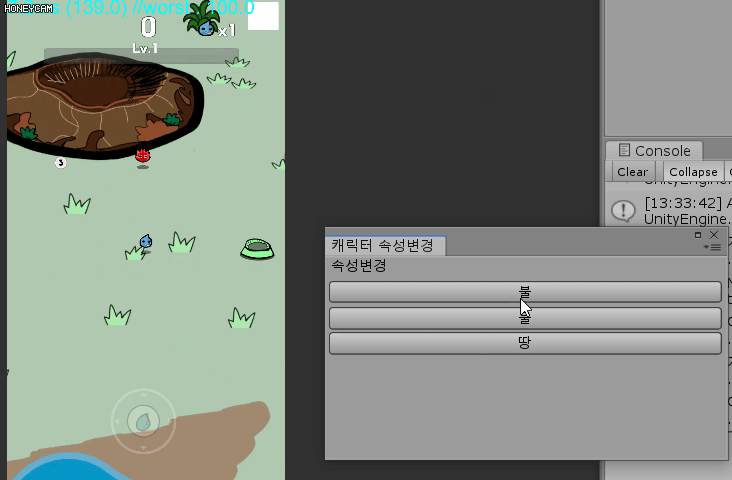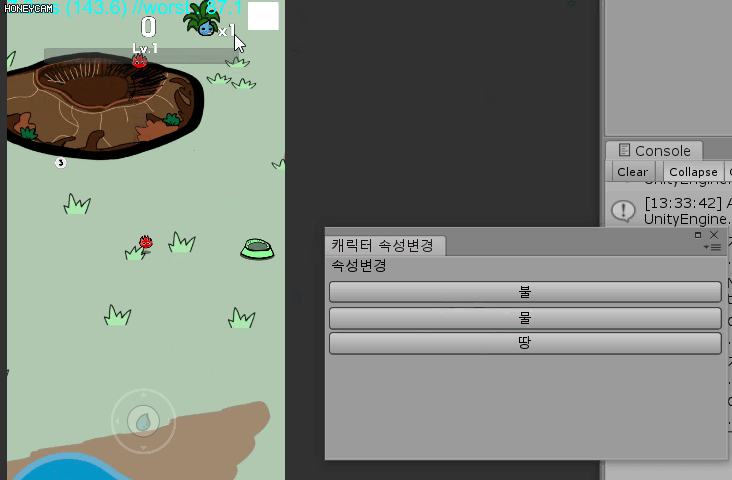
아래 그림처럼 스켈레톤 몬스터는 모두 같은 머티리얼을 사용하고 있다. 그러면 현재는 한 개의 인스턴스가 있는 것이다. 그런데 플레이어가 스켈레톤을 공격하면 빨간색으로 피격 효과를 받게 되는데 같은 인스턴스를 공유하고 있기 때문에 피격을 당하지 않은 몬스터까지도 피격 효과(빨갛게) 변할 것이다.
이것은 분명 개발 기획의도는 아닐 것이다. 그렇다면 어쩔 수 없이 몬스터마다 각각 다른 인스턴스를 생성해서 적용해야 하는 걸까?
MaterialPropertyBlock를 이용하면 객체의 변화를 주는 동안만 배칭이 되지 않고 작업이 끝나면 다시 배칭을 하는 방법이다.
8. 스태틱배칭
스태틱 배칭은 말 그대로 정적인 오브젝트 즉 움직이지 않는 오브젝트를 위한 기법이다. 주로 배경 오브젝트들이 해당되는데 이 기법을 이용하려면 Static 플래그를 켜야 한다. 이 플래그를 켜야 유니티가 이 오브젝트는 움직이지 않는 스태틱 오브젝트라는 것을 알 수 있기 때문이다.
그런 후 다른 작업 없이 게임을 시작하면 자동으로 유니티는 스태틱 플래그가 켜진 오브젝트를 배칭 처리 작업을 진행한다. 오브젝트 버텍스가 많을수록 렌더링 연산 비용이 크다. 당연히 버텍스 수가 많으면 런타임 과정 중에 부담이 크다. 하지만 스태틱 배칭 된 오브젝트는 런타임에 연산이 이루어지지 않는 게 장점이 되는 것이다.
드로우콜수를 줄이기 위해 오브젝트들을 합쳐 내부적으로 하나의 메시로 만들어준다. 만일 3개의 오브젝트가 1개의 메시만 사용하더라도 3개의 메시를 합친 만큼 추가 메모리가 필요하게 되는 것이다. (내 생각에는 SpriteAtlas처럼 생각하면 될듯하다)
물론 이 작업은 유니티가 이러한 정보들을 저장해 야하기 때문에 메모리가 조금 더 필요하게 된다. 렌더링(드로우 콜)이냐 메모리냐 이 논제는 최적화에서 자주 결정해야 할 사항이다. 스태틱 배칭을 간단하게 정의하자면
대상 :움직이지 않는 오브젝트
장점 : 드로우콜 감소
단점 : 메모리 증가
9. 다이내믹 배칭
동적으로 움직이는 오브젝트들끼리 배칭 처리를 하는 기능이다. 동일한 머티리얼을 사용하며 자동으로 배칭이 이루어진다. 배칭 처리는 런타임상에 이루어지며 Static플래그가 체크되어 있지 않는 오브젝트들의 버텍스들을 모아서 합쳐주는 과정을 거친다. 이러한 버텍스들을 모아서 다이내믹 배칭에 쓰이는 버텍스 버퍼와 인덱스 버퍼에 담는다. GPU는 이를 가져가서 렌더링 하는 것이다. 매프 레임 데이터 구축과 갱신이 발생하기 때문에 오버헤드가 발생하게 된다. 다이내믹은 자동으로 이루어지지만 여러 가지 조건들이 있다.
1. 버텍스 900개 이하로 된 메시로만 적용된다.
2. 트랜스폼을 미러링 한 오브젝트들은 배칭 되지 않는다.(예를 들어 Scale값이 1인 오브젝트를 -1로 적용했을 때)
3. 다른 머티리얼 인스턴스를 사용하면 같이 배칭 되지 않는다.
4. 라이트맵이 있는 오브젝트는 추가 렌더러 파라미터를 가지는데, 일반적으로 동적으로 라이트 매핑된 오브젝트가 완전히 동일한 라이트맵의 지점에 있어야 배칭 된다.
5. 멀티 패스 셰이더를 쓰면 배칭이 되지 않는다.
스태틱 배칭은 버텍스 쉐이더에서 월드 스페이스로의 변환이 이루어진다. 즉 GPU에서 연산이 된다. 하지만 다이내믹 배칭은 실시간으로 오브젝트의 위치가 변환되기 때문에 CPU에서 연산이 이루어진다.
10. 2D 스프라이트 배칭
2D도 배칭 작업이 가능하다. 텍스처 아틀라스 기법처럼 여러 이미지들을 한 이미지에 모아서 사용하는 방법과 SpriteAtlas를 사용하여 배칭 처리한다.
적은 수의 드로우 콜을 사용하여 동일한 메시의 여러 복제본을 한 번에 그리거나 렌더링 한다. 특히 씬에서 반복적으로 나타나는 건물, 나무, 풀 등의 오브젝트를 보여줄 때 좋다. 또 같은 메시를 사용하더라도 간단한 변화 컬러, 스케일 등의 변화를 줄 수 있다. 별도의 메시를 메시를 생성하지 않기에(트랜스폼 정보를 별도의 버퍼에 저장) 다이내믹 배칭과 스태틱 배칭보다 오버헤드가 적다.
드로우콜을 이해 하려면 데이터와 명령의 흐름을 알아야한다. 먼저 메시,텍스처 등 렌더링에 필요한 데이터들은 저장소 흔히 알고있는 HDD,SDD,SD에 먼저 위치한다. 그러고 CPU는 이 데이터들을 파싱하여 CPU메모리에 데이터를 옮긴다. 그 그런 후 마지막으로 GPU는 CPU의 메모리의 데이터들을 GPU메모리에 복사를 하게된다.
예를들어 GPU가 메시를 렌더링할 때 지오메트리 데이터를 GPU메모리에서 가져와 렌더링하게 된다. (GPU메모리에 렌더링에 필요한 데이터가 있다고 보면 됨)
메모리를 가져오고 전달하는 과정을 매프레임 때마다 하는것은 성능저하가 올 수 있기 때문에 특정 시점(로딩 시점, 씬전환시점)에 메모리 데이터를 올려 사용하도록 하는게 좋다. 계속해서 사용하는 데이터라면 메모리에 계속 올려두고 사용하고 그럴필요가 없는 메모리라면 데이터를 해제해 메모리 부담이 없도록 한다. 메모리에 영향이 없다면, 특정시점에 한번에 해제하는 것도 방법이다.
3. 커맨드 버퍼 (Command Buffer)
렌더링은 CPU가 바로 GPU에 명령을 보낸다고 생각하지만 중간에 GPU가 할일을 보관하는 중재자가 있다. CPU와 GPU는 병렬작업을 통해 수행하는데 이러한 과정을 중재하는 커맨드버퍼가 있다. CPU가 GPU에게 명령을 하는 순간 GPU가 다른 일을 하고 있을 수 있기 때문에 그 명령을 쌓아 놓고 순차적으로 GPU가 처리 할 수 있도록 한다.
4. CPU의 성능에 의존되는 드로우콜
렌더링이기 때문에 드로우콜은 CPU보다는 GPU의 영향이 크다고 생각하지만, GPU가 그리기 위한 신호들을 모두 CPU가 GPU에 맞게 변형하여 보내게된다. 이런 과정들은 곧 CPU바운더리의 오버헤드이며, 텍스쳐의 크기를 줄이거나, 폴리곤 수를 줄인다고 해서 드로우콜의 성능이 좋아지는 것은 아니다. (횟수를 줄여야함)
5. 배치와 SetPass Call
드로우콜의 발생조건을 이해하기 전에 먼저 배치(Batch)와 SetPass를 알아야한다. 배치는 각각의 드로우콜 사이에서 그래픽스 드라이버 유효성 체크를 진행할때, GPU에 의해 접그되어지는 리소스들을 변경하는 일련의 작업들을 총칭한다. (드로우콜과 혼용하여 사용하지만 드로우콜을 포함하는 상위 개념인것이다.) SetPass는 쉐이더로 인한 렌더링 패스 횟수를 의미하고 쉐이더의 변경 시 SetPass카운트는 증가하게된다. 드로우콜이 일어날때 상태 변경의 발생 여부로 이해하면 된다. (메시 변경은 포함하지 않음)
유니티 Stats를 보면 간단하게 몇번의 배치가 됐는지 볼수 있다.
6. 드로우콜의 발생 조건
오브젝트 하나를 그릴때 메시1개, 머테리얼도 1개로 이루어져있다면 배치는 1이다.(드로우콜 한번), 하지만 하나의 오브젝트가 여러 파츠로 나눠져있고, 메시가 여러개이면 하나의 머테리얼을 공유했다고 해도 파츠 수 만큼 드로우콜이 발생한다. 이러한 오브젝트가 여러개있다면 파츠수 x 오브젝트수 = 드로우콜 수 가되는것이다. 때로는 당연히 성능에 많은 영향을 미칠수 있다. 메시가 여러개인 경우말고도 머테리얼이 여러개 인 경우, 툰쉐이딩 처럼 외각선을 그리기위해 멀티패스로 이루어져있는 쉐이더를 사용하면 두번의 드로우콜이 발생하게 된다.
TCP/IP는 4단계 층으로 구성되는 계층적 프로토콜이다. 가장 하위 계층에는 네트워크 접속 계층이 있는 이는 하나의 계층으로 정의하기도 하고 또는물리 계층과 네트워크접속 계층, 2개의 계층으로 정의하기도 한다. 그 다음 패킷을 목적지까지 전송 책임을 수행하는 인터넷 프로토콜계층 그리고 종단간 신뢰성있는 연결을 수행하는 세그먼트 단위의 정보교환을 담당하는 전송 계층이 있으면 마지막으로 송수신지 응용 프로세스 사이 정보의 처리 기능을 수행하는 응용프로세스 계층이 있다.
응용 계층
응용 계층은 원격의 프로세스 혹은 응용들 사이에 통신을 제공한다. HTTP, FTP, Telent, SMTP, SNMP기반의 응용서비스가 수행되는 계층이다.
HTTP웹 서비스를 제공하는 응용 계층 프로토콜이다.
FTP파일 전송에 사용되는 프로토콜로서 파일의 전송을 위해 두개의 연결이 생성된다. 하나는 원격 시스템에 제어정보 송수신을 위해 연결된다. 그리고 연결 후 파일 전송을 위해 또 다른 연결이 수행된다.
Telnet과 SMTP
SNMP
전송 계층
1. TCP
전송 계층 프로토콜은 TCP와 UDP가 있다. TCP 프로토콜은 두 종단 호스트간에 신뢰적인 연결형 서비스를 제공하여, 전송메세지의 정확한 수신지 도착 여부의 확인을 보장한다. 즉 시간 초과와 오류 재전송 그리고 데이터 흐름제어 기능이 제공된다.
네트워크 계층인 IP계층에서는 비연결형을 지향하므로 네트워크에 대한 에러제어와 흐름제어 기능을 수행하지 않기 때문에 TCP전송계층에서 에러제어와 흐름제어 기능이 제공된다.
2. UDP
UDP프로토콜은 비연결형 서비스를 지원한다. UDP의 특징은 수신측에 패킷이 도착했는지 확인 여부를 보장하지 않으며 흐름제어의 기능을 제공하지 않는 비신뢰적인 서비스를 제공한다. 그러므로 수신된 데이터 훼손에 따른 무결성을 보장받지 못하므로 암호화기술이 적용될 수 있다. 네트워크 혼잡 시에 데이터 일부가 소실된다 하더라도 확인 작업이나 재전송 서비스가 지원되지 않는 특징을 가진다. UDP서비스는 제어용의 작은 메세지 혹은 재전송이 필요 없는 동영상 정보전송에는 적절한 서비스가 될 수 있다.
클라이언트 프로그래머(초짜)지만 업무에 네트워크의 기본적인 지식은 필요하다고 생각되어 오늘부터 공부를 시작해보려고 한다!
네트워크
네트워크 구성
네트워크를 구축한다는 것은 사용자와 홈 그리고 사무실 등을 물리적 통신 설비를 기반으로 표준 통신 프로토콜로 연결하여 네트워크를 구축하는 것을 의미한다. 또한 네트워크는 또 다른 네트워크로 연결되어 거대한 인터넷으로 구성된다.
네트워크를 구성하는 물리적인 개념에서 하드웨어기반의 구성요소가 필요한데, 그 예로 라우터, 스위치, 이더넷 카드, 커넥터 허브 등이 있고, 서버 시스템과 개인용 컴퓨터 같은 호스등이 있다.
네트워크 구성요소
기능
라우터
IP주소기반 다른 네트워크와 통신 가능 장비
스위치
이더넷 주소기반 다음 목적지 회선 선택 장비
커넥터(RJ-45)
다양한 통신장비를 네트워크로 연결
이더넷 카드
단말기에 연결되어 데이터 송수신 역할
모뎀,허브,공유기
데이터전송을 위한 통신 주변 장치
네트워크를 구성하게 되면 거리와 공간의 제약을 극복하여 많은 정보기술의 다양한 장점을 활용할 수 있다. 먼저, 같은 네트워크 스토리지와 백업 장치를 비롯한 하드웨어와 소프트웨어 자원들 그리고 수많은 데이터와 응용 프로그램들의 공유가 가능하다.
TCP / IP 프로토콜
표준 네트워크 프로토콜 기반의 인터넷에서는 네트워크 주요 서비스인 이메일 서비스,포털서비스와 게임 등 실시간으로 정보를 주고받는 애플리케이션 서비스를 어디서든지 이용할수 있게 된다. 네트워크 구축을 위해 사용되는 표준 프로토콜은 인터넷에서 사용되는 TCP/IP 프로토콜이다. TCP/IP 프로토콜을 이용하여 여러 토폴로지 형태의 네트워크를 연결한 것이 인터넷이다. 그리고 TCP/IP 프로토콜을 이용하여 내부 네트워크를 연결하여 내부 네트워크 사이 통신을 가능하게 한것이 인트라넷이다.
머테리얼의 속성을 변경할때 SharedMaterial으로 색상을 바꾼다던지 쉐이더코드의 프로퍼티값들을 변경한다. 그런데 이 런타임중에 변경된 머테리얼의 값들은 종료해도 바뀐 값 그대로 유지된다. 이것을 봤을때 Material에셋과 대응한다고 볼 수 있다.
같은 머테리얼을 가지고 있는 오브젝트
sharedMaterial을 사용하면 같은 머테리얼을 사용하는 모든 오브젝트가 변경된다. 예를들어 플레이어가 공격한 몬스터에게 림라이트효과를 주고 싶어 피격받은 몬스터의 Rim의 굵기를 변경했는데, 주위 모든 몬스터들의 Rim의 굵기가 변경되는것이다. => sharedMaterial을 참조하여 렌더링하기 때문 (배치 렌더링)
하지만 피격한 몬스터의 Rim만 변경을 원하기에 Renderer.material로 특정 오브젝만 변경할 수 있다.
복사본을 생성(Instance)하는 Renderer.material
값을 변경을 하지 않아도 Renderer.material을 참조하는 순간!, 사본이 생성된다. 당연히 사본을 생성했기에 배치 랜더링이 되지않는다.
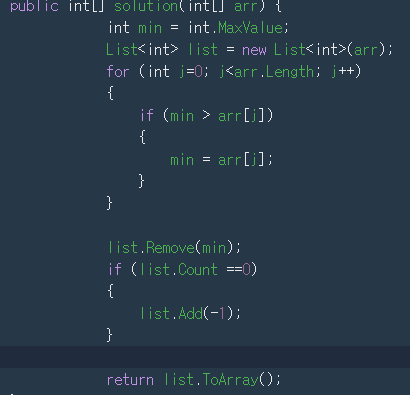
입력된 int [] 형식 배열중에 가장 작은 수를 구해서 제거해주는 과정이 고려해야 할 부분이다.
내 풀이
list에 옮겨 담고 각 요소를 비교하며 가장 작은 수를 뺀 리스트를 배열로 변환하여 반환했다.
다른 사람 풀이
Linq를 사용하여 배열의 요소들 중 최솟값을 구하고 Where으로 조건을 두어, 아까 구한 최소값을 제외한 요소들로 배열로 만들었다. Linq가 사용은 간편하게 원하는 값을 받아 올 수 있다는 장점이 있지만 속도가 느리다는 점에서 유니티 개발에서는 적절히 사용?을 해야 할 듯싶다.