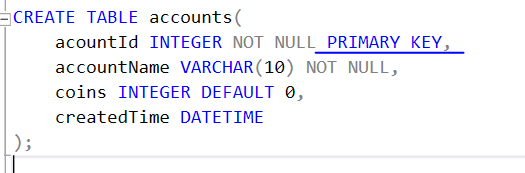
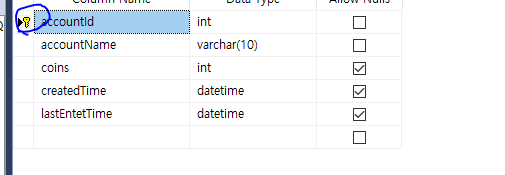
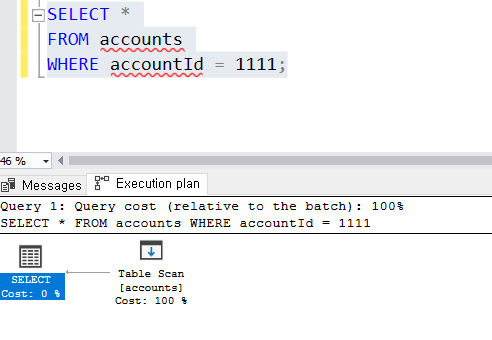
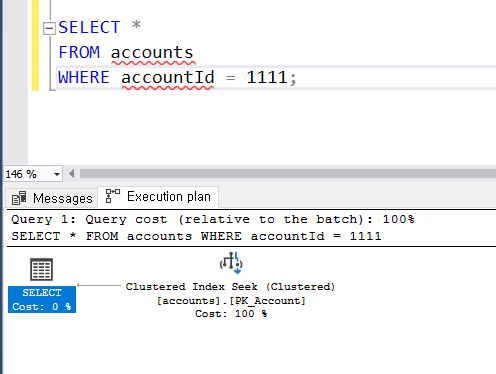
이 시점(현재 경력)에서 이런 글을 작성하는데 시간을 쓰는 것보다, 자료구조 공부 또는 알고리즘 문제를 한 문제 더 푸는 것이 더 좋다고 생각도 했지만 하지만 이렇게 나의 생각을 한 번쯤은 정리해보고 싶은 생각이 들었다.
좋은 코드를 작성하는 방법은 무엇일까?
좋은 코드란? 좋은 코드는 빠르게 읽히고 유지보수가 쉬우며 수정사항이 있을 때 몇 개의 함수 호출로 원하는 기능을 수정/추가가 가능한 코드일 것이다.
하지만 기업에서 많은 사람들의 협업을 통해 업무가 진행되는 프로그램에서 이런 코드는 현실적으로는 힘들어 보인다.
버그를 수정할 때는 현재 수정하려는 부분에서 코드들의 한 줄 한 줄 의미를 파악해야 하며 수정했을 때 발생할 사이드 이펙트에 관해서도 꼼꼼히 살펴야 한다. 이 코드는 그럴 것이다~ 또는 누군가가 작성한 함수의 이름만 믿고 그런 기능을 하는 함수겠지 하는 생각으로 대충 리딩하고 버그를 수정하다 보면 나중에 크게 데일수 있다.. 그렇기 때문에 우리는 좋은 코드를 작성하려고 노력해야 한다.
이런 좋은 코드들이 나중에 프로그램이 실제로 서비스됐을 때 버그 수정에서도 빠르게 수정이 됐었고, 그 좋은 코 드위에서 작업을 할 때도 그렇지 않은 코드보다 훨씬 시간이 감축됐다. (어느 위치에, 어느 함수에 있어야 할 기능이 딱딱 있었다.)
좋은 코드를 작성하는 방법은 주어진 상황에 맞는 판단하여 작성하는 코드가 아닐까 한다.
서비스하려는 프로그램을 만들다 보면 당연히 현재 코드가 실제 서비스됐을 때 새로운 기능은 쉽게 수정/추가/제거가 가능한지, 발생 가능한 이슈들을 예상하며 만들게 된다. 이러한 코드 작성은 당연히 시간이 많이 소요된다.
근데, 이 상황에서도 우리가 지향하는 좋은코드로 작성하는 게 맞을까?
예를 들어, 나에게 업무가 할당됐다. 그 업무는 이틀 안에 3가지 프로토타입을 발표하고 그중에서 선택받은 프로그램으로 본격적인 개발을 하기로 했다.
그런데 미래 확작성을 고려한 베이스 코드부터 여러 기능을 미리 만들어 놓고 유지보수도 생각하면서 개발하다 설계과정에서부터 많은 시간이 소요돼 기한 내에 업무를 처리하지 못할 수 있다. 정작 결국에 사용하지 않을 코드나 기능을 만드는데 시간을 쓴 것이다. 그렇다면 코드로만 봤을 때 좋은 코드일 수는 있어도 좋은 코드 작성방법에서는 맞지 않는다고 생각한다.
당연히 프로토타입을 만드는 과정에서도 수정사항과 여러 이슈가 발생할 수 있다.
말하고 싶은것은 작성하려는 상황에서 개발 속도와 그 상황에 어느 정도 예상되는 유지보수성까지만 살려 적절하게 작성하는 것이다.
시간이 돈으로 연관되는 이런 상황에서 이 두 개의 중점을 잡기는 힘들다. 업무를 하면서 이런 판단을 해야 할 일들이 많았고 또, 그 판단 결과가 만족스럽지 않은 적이 많았다. 이런 판단을 하려고 노력하다 보면 이 경험들이 점차 좋은 판단력을 얻어지지 않을까 생각한다.
int[] arry = newint[20000001];
int n = int.Parse(Console.ReadLine());
string[] nstr = Console.ReadLine().Split(' ');
int m = int.Parse(Console.ReadLine());
string[] mstr = Console.ReadLine().Split(' ');
int nIdx = 10000000;
StringBuilder stringBuilder = new StringBuilder();
for (int i = 0; i < nstr.Length; i++)
{
arry[nIdx + int.Parse(nstr[i])]++;
}
for (int i = 0; i < mstr.Length; i++)
{
stringBuilder.Append(arry[nIdx + int.Parse(mstr[i])] + " ");
}
Console.WriteLine(stringBuilder.ToString());
단순히 이중for문으로 풀수도있지만 시간초과가 날수 있기 때문에 카운트소팅으로 문제를 해결했다. 카운트할 갯수를 저장한 배열을 선언하다 범위가 [-10,000,000보다 크거나 같고, 10,000,000보다 작거나 같다] 이기 때문에 배열크기를 20,000,001로 할당했다.
예를들어 -9000000 이 값이 나오면 10000000을 더해 1000000인덱스에 접근하여 1을 더해준다.
그렇게 하면 다른 조건처리 없이 배열의 값을 할당할 수 있기 때문이다.20,000,000이 아닌 20,000,001인 이유는 0의 카드도 나올수 -10000000인 카드가 나오면 배열의 인덱스는 0을 가리키기 때문이다.
알파벳 소문자로만 이루어진 단어 S가 주어진다. 각 알파벳이 단어에 몇 개가 포함되어 있는지 구하는 작성하는 문제이다.
풀이 : 내가 작성한 코드
처음 생각했을 때는 입력된 string값을 기준으로 또 다른 a~z을 체크하여 입력된 string요소의 알파벳이 해당하는 수를 카운팅 해서 추 출력하려고 했다.그러면 총 O(N^2) 시간 복잡도였다. 다른 방법으로는 미리 a~z의 해당하는 26개 크기를 가지는 배열을 미리 생성했다. 그렇게 하면 a~z까지 각각의 string요소의 해당하는 알파벳에 위치가 정해 지므로, 입력값의 요소로 for문을 돌리면서 해당하는 알파벳에 1씩 증가해 주면 된다.
우선순위와 인덱스를 갖는 Task라는 클래스를 만들어서 Queue에 넣도록 했다. 그런 후 foreach로 하나씩 검사하여 자기보다 뒤 에이 있는 값이 우선순위가 높다면 반복문을 빠져나와 맨뒤로 넣도록 했다. 선입선출이기 때문에 큐를 사용했다. 모든 값들을 정렬할 필요가 없기 때문에 nNow인 순서를 체크하는 변수와 매개변수 location이 같으면 값을 출력해준다.
풀이 : 다른 사람이 작성한 코드
나는 큐에 우선순위와 인덱스 값을 저장할 클래스를 따로 만들었지만 이 코드에서는 KeyValuePair를 사용했다. While문을 돌리면서 큐에 들어가 있는 값들 중에 가장 높은 우선순위의 값이 큐의 맨 처음에 입력된 값과 우선순위를 비교한다. 가장 큰 값이 현재 입력 순서라면 매개변수 location과 비교한다. 그 값이 location도 아닌데 가장 큰 값이면 answer를 하나씩 증가한다. 출력 순서가 아니란 얘기다.
자주 사용하는 데이터나 값을 미리 복사해 놓는 임시 장소를 가리킨다. 원래의 데이터를 접근하는 시간이 오래 걸리거나 반복적으로 동일한 결과를 돌려주는 경우 데이터를 직접적인 접근으로 인한 병목현상을 막기 위해 사용되는 저장소이다.
캐시 철학
Temporal locality
시간적으로 보면, 최근에 사용했던 기억 장소들이 집중적으로 액세스 되는 경향이 있다. 접근되었던 적이 있는 곳에는 다 시 접근할 가능성이 높다는 판단
Spacial locality
프로그램 실행 시 접근하는 메모리의 영역은 이미 접근이 이루어진 영역의 근처일 확률이 높다.
테스트 코드
int[,] arr = newint[10000, 10000];
{
long now = DateTime.Now.Ticks;
for (int i = 0; i < 10000; i++)
{
for (int j = 0; j < 10000; j++)
{
arr[i, j] = 1;
}
}
long end = DateTime.Now.Ticks;
Console.WriteLine($"(i,j) 순서 걸린 시간{end - now}");
}
{
long now = DateTime.Now.Ticks;
for (int i = 0; i < 10000; i++)
{
for (int j = 0; j < 10000; j++)
{
arr[j, i] = 1;
}
}
long end = DateTime.Now.Ticks;
Console.WriteLine($"(j,i) 순서 걸린 시간{end - now}");
}
테스트 결과로 봤을 때 같은 동작이지만 두 개의 결과가 많은 시간이 차이가 보이는 걸 알 수 있다. Spacial locality관점으로 근접한 공간적 메모리 영역을 접근했을 때 좀 더 짧게 수행되기 때문이다.
Google sheet to Json이라는 에셋을 추가했을 때 발생 Newtonsoft.Json.dll이 중복으로 있어 문제인 거 같았다.
오류 해결방법
추가한 GSpreadSheets 폴더
Library\PackageCache에 있는
Library\PackageCache\com.unity.nuget.newtonsoft-json@2.0.0\Runtime에 있는 Newtonsoft.Json.dll를 제거해준다.
느낀 점
내가 사용하는 유니티 프로젝트 버전은 2021 버전으로 최신을 낮은 버전으로 Google sheet to Json에셋을 추가했을 때는 아무 문제가 없었다. 검색한 본 걸로는 2020? 버전부터 패키지에 com.unity.nuget.newtonsoft-이 추가되어있는 것 같다. 최신 버전의 유니티에 에셋들은 아직 버전 대응이 되지 않았던 것 같다. 유니티 버전을 바꾸면서 고려야 해야 할 사항을 체크가 필요할 것 같다.
리스트에 같은 수의 데이터를 넣고 지우 고를 반복했을 때 걸리는 시간 체크하기. 여기 포인트는 미리 정해놓은 Cpaacity의 크기를 넘지 않을때이다.
테스트 코드
long lPre = System.GC.GetTotalMemory(false);
int tick1 = Environment.TickCount;
List<int> list = null;
if (bCapacity)
list = new List<int>(10000000);
else
list = new List<int>();
for (int k = 0; k < 10; k++)
{
for (int i = 0; i < nCount; i++)
{
for (int j = 0; j < nCount; j++)
{
list.Add(i + j);
}
}
}
int tick2 = Environment.TickCount;
long lAfter = System.GC.GetTotalMemory(false);
Debug.LogError(string.Format("Capacity Use : {0} | list Count : {1} / Tick : {2}/ Memory : {3}",
bCapacity, list.Count, tick2 - tick1, lAfter - lPre));
Capacity를 크기를 미리 설정한 케이스가 시간이나 메모리가 더 적게 발생하는 걸 알 수 있다.
두 번째 테스트
재 할당될 때 List의 Capacity변화를 테스트해봤다.
테스트 코드
List<int> list = new List<int>();
Debug.LogError(list.Capacity);
list.AddRange(newint[4] { 1, 2, 3, 4 });
Debug.LogError(list.Capacity);
list.Add(1);
Debug.LogError(list.Capacity);
처음에 4개의 데이터를 넣고 그 범위를 초과할 때 Capacity를 로그 찍어봤다.
테스트 결과
데이터의 수는 4개에서 5개로 1개 증가했지만 현재 사이즈의 2배만큼 Capacity를 할당된 것을 알 수 있다.
오늘 테스트 최종 결과
List에 사용하는 최대 크기를 안다면 Capacity를 미리 설정해두는 것이 좋다. List는 현재 가지고 있는 Count수가 초과될 때 기존의 데이터를 복사한 후 다시 2배 사이즈로 재할당하게 된다(기존의 있던 데이터는 가비지 해제 대상으로 잡히게 된다.) 만약 할당된 Capacity를 현재 데이터의 수만큼 변경하고 싶으면 TrimExcess 을 이용한다.
SoketFlags.Peek : 소켓 전송 및 수신 동작을 지정(Peek:들어오는 메시지를 미리 본다)
=> 1바이트를 보내고 실제 수신된 바이트를 확인하여 연결여부를 확인한다.
다시 위쪽에 else부분을 살펴보면,
else
{
NetworkStream s = c.tcp.GetStream();
if (s.DataAvailable)
{
string data = new StreamReader(s, true).ReadLine();
if (data != null)
OnIncomingData(c, data);
}
}
TcpClient.GetStream() : 데이터를 보내고 받는 데 사용되는 NetworkStream을 반환한다.
NetworkStream.DataAvailable() : 데이터를 읽을 수 있는지 여부를 나타내는 값을 가져온다.( 읽을 수 있으면 true, 그렇지 않으면 false)
이제 NetworkStream.DataAvailable() 까지 성공했다면 밑에 함수를 통해
빌드된 프로젝트를 돌렸을때 데이터와 이미지들이 빠진 상태로 진행되지 않는 현상이 있었다. 번들이 다운로드가 완료되지 않은 상태에서 이미지를 가져오려고 하는 경우였다. 유니티 에디터에서는 번들을 다운로드 하는 과정이 없이 진행되기에 오류가 발생되지 않아서 놓치고 있던 부분이었다.
오류 해결방법
번들을 모두 완료됐다고 됐을 경우에 게임이 진행될수 있도록 셋팅한다.
수정 전
우선 문제가 되는 부분은 LoadAssetAsyncGameObject이라는 위 함수안에 Addressables.LoadAssetsAsync()가 타입별로 한번만 실행되는줄 알았다. 하지만 EmAssetType타입의 해당하는 모든 객체가 로드될때마다 동작된다.
수정 후
AsyncOperationHandle<IList<Object>> handle의 IsDone을 현재 에셋이 모두 불러와졌는지 체크할수 있었다.
+) 어드레서블에는 유니티 에디터에서 번들을 불러오는 것처럼 테스트할수 있는 기능이 있다
느낀점
느낀점은 어드레서블의 기능을 완벽히 숙지 못하고 코드를 설계했다. 코드 한줄 한줄 모두 이해하고 적용해야한다는것을 다시 깨닫게 되었다.